Introducción
En este documento trataremos de hacer una breve introducción al monitoreo de aplicaciones, específicamente con herramientas como Kubernetes, Prometheus y Grafana, entre otras.
Más que nada apunta a ser una guía práctica para poder desplegar nuestra aplicación, recopilar información sobre la misma y poder consumirla mediante dashboards, con el fin de detectar, prevenir y mejorar nuestros servicios de cara al usuario final.
El enfoque será en un ambiente local, donde podremos desplegar nuestra app en un cluster. Esto es con el fin específico de que uno, al momento de desarrollar, pueda monitorear cómo se comporta cada servicio, tanto a nivel de aplicación (requests, read/writes a la BD) como al de infraestructura (CPU, memoria, redes).
Vale mencionar que existen herramientas cloud que también nos permiten llevar a cabo todo esto, como EKS de AWS, GKS de Google Cloud y AKS de Azure y Grafana Cloud de Grafana.
Requisitos
- docker
- kubectl
- kind
- helm
- node
Desde un repositorio hasta un cluster
¿Cómo pasamos de un repositorio a un cluster? Bueno, precisamente pasamos a un nodo dentro de un cluster. Cada cluster puede tener varios nodos, generalmente cuenta con un master node y con otros workers nodes. Pero lo que nos interesa aquí es poder "alojar” nuestro código dentro del cluster, que en última instancia es lo que será monitoreado.
Primer paso: creando nuestra imagen
Asumiendo que ya tenemos nuestro microservicio listo, o al menos funcionando, lo primero que vamos a hacer es crear un archivo Dockerfile en la raíz del repositorio. Se vería como algo así:

La versión de Node dependerá de la versión que utilices en tu microservicio. Lo mismo para el puerto en que hayas elegido servir tu aplicación.
Una vez que tenemos el archivo listo, en nuestra consola, parados en el proyecto, correremos: docker build -t <image:latest> .
En el comando de arriba tendremos que reemplazar <image:latest> con el nombre que le queremos dar a nuestra imagen, por ejemplo: <identity:latest>
El punto al final del comando es para indicar donde tiene que buscar el Dockerfile para construir la imagen. Entonces, nos quedaría así:
docker build -t identity:latest .Ahora si corremos un docker images deberíamos poder ver nuestra nueva imagen:
Aquí podemos ver múltiples imágenes ya que varias fueron creadas. A modo de ejemplo, podemos ver la imagen de identity con el tag latest.
Con respecto a las imágenes kindest/node y node, son imágenes que fueron creadas automáticamente con el paquete Kind (Kubernetes in Docker) al momento de crear un cluster con dicha herramienta, que es en lo que nos centraremos a continuación.
Segundo paso: creando un cluster con Kind
Como recién comentábamos, para crear un cluster utilizaremos Kind. Es una herramienta para crear, correr y administrar clusters locales de Kubernetes usando contenedores de Docker.
Crear un cluster es bastante simple:
kind create cluster --name identityKind va a construir un cluster con un nodo llamado kind-identity. Para ver la cantidad de nodos en nuestro cluster, usaremos la herramienta kubectl:
kubectl get nodes
Ahora ya tenemos nuestro cluster creado. Lo siguiente es cargar nuestra imagen de Docker del microservicio de identity al cluster de Kind.
Tercer paso: cargando nuestra imagen al cluster
Para poder monitorear nuestro microservicio, primero, tenemos que cargarlo al cluster, porque es lo que se monitorea realmente. Siguiendo nuestro ejemplo:
kind load docker-image identity:latest --name identityAquí lo que estamos haciendo es, justamente, cargar la imagen que construimos a partir del microservicio de identity a nuestro cluster de Kind.
Ahora que tenemos un cluster funcionando, con una imagen de nuestro microservicio y todo, veamos el cluster desde adentro:

El comando utilizado fue
kubectl get all -n kube-systemEn la imagen se pueden apreciar varios servicios o componentes, por ejemplo, los de Prometheus, que es una herramienta para hacer queries y obtener data sobre nuestros clusters, para poder ser posteriormente consumida.
Todo cluster tiene un control plane o plano de control, que es el nodo maestro. En este nodo es donde los principales componentes del clúster están alojados.
El comando de arriba nos permite consultar información específica del cluster, en este caso del namespace kube-system. Dentro de un cluster podemos tener varios namespaces.
Podemos obtener todos los namespaces de nuestro cluster con:
kubectl get namespace
Podemos ver que hay varios namespaces, y particularmente monitoring es el único que no fue creado por default.
Cuarto paso: deployando con Helm
Helm es otra herramienta que nos permite interactuar con nuestro cluster: instalar, manejar, deployar y actualizar recursos. Es como package manager para Kubernetes.
Lo primero que vamos a hacer es pararnos en la raíz de nuestro proyecto y ejecutar
helm create chart-nameEsto creará un archivo values.yaml y una carpeta /templates. Dentro de la carpeta tendremos diferentes archivos de tipo YAML, que son básicamente archivos de configuración para el deploy de servicios y recursos en nuestro cluster. Estos archivos tomarán valores para sus variables del archivo values.yaml. Sin embargo, nos concentraremos en este último archivo, siendo que desplegaremos nuestro cluster con dos herramientas enfocadas en el monitoreo, Prometheus y Grafana:

Al momento de crear nuestro Helm chart, este archivo se verá diferente, con muchas más configuraciones, pero lo importante son estos dos servicios, Prometheus para recolectar información y Grafana para poder consumirla mediante dashboards. Agregar lo siguiente al archivo:
prometheus:
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelector: {}
serviceMonitorNamespaceSelector: {}
scrapeTimeout: "90s"
scrapeInterval: "90s"
grafana:
sidecar:
datasources:
defaultDatasourceEnabled: trueUna vez que creamos nuestro chart, tendremos que agregar el kube stack de Prometheus a nuestro Helm Registry, que es como un repositorio, para que nuestra instalación local de Helm esté al tanto:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
Este repositorio contiene nuestros charts (que pueden ser varios). Luego actualizamos nuestro chart: helm repo update
Vamos a crear un namespace para desplegar nuestro chart y servicios de monitoreo:
kubectl create ns monitoringSuele ser buena práctica mantener nuestros charts y servicios separados, dependiendo de la lógica/fin de los mismos.
Ahora que tenemos todo podemos instalar nuestro chart y todos sus servicios:
helm upgrade --install prom prometheus-community/kube-prometheus-stack -n monitoring --values values.yamlVeremos un mensaje como este en la consola:
❯ helm upgrade --install prom prometheus-community/kube-prometheus-stack -n monitoring --values values.yaml
Release "prom" does not exist. Installing it now.
NAME: prom
LAST DEPLOYED: Fri Jul 14 16:31:37 2023
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=prom"
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
Listo, nuestro Helm chart fue instalado y deployado a nuestro cluster de Kind.
Quinto paso: dashboards en Grafana
En este último paso veremos como nos conectamos a nuestra aplicación corriendo en el cluster, para poder consumir data y mostrarla en dashboards. Lo haremos mediante port-forwarding:
kubectl port-forward service/prometheus-operated -n monitoring 9090:9090Nos conectamos al servicio de Prometheus para consumir data. Para conectarnos a Grafana y ver la data en dashboards:
kubectl port-forward service/prom-grafana -n monitoring 3000:80Vamos a localhost:3000 y las credenciales serán:
username: admin
password: prom-operatorEn Grafana contaremos con múltiples dashboards predeterminados, sin embargo también se pueden crear algunos personalizados. El dashboard de nodes es especialmente útil, ya que nos permite ver información relacionada al nodo (corriendo dentro del cluster) y los recursos que consume en el sistema operativo. Veremos algo así:
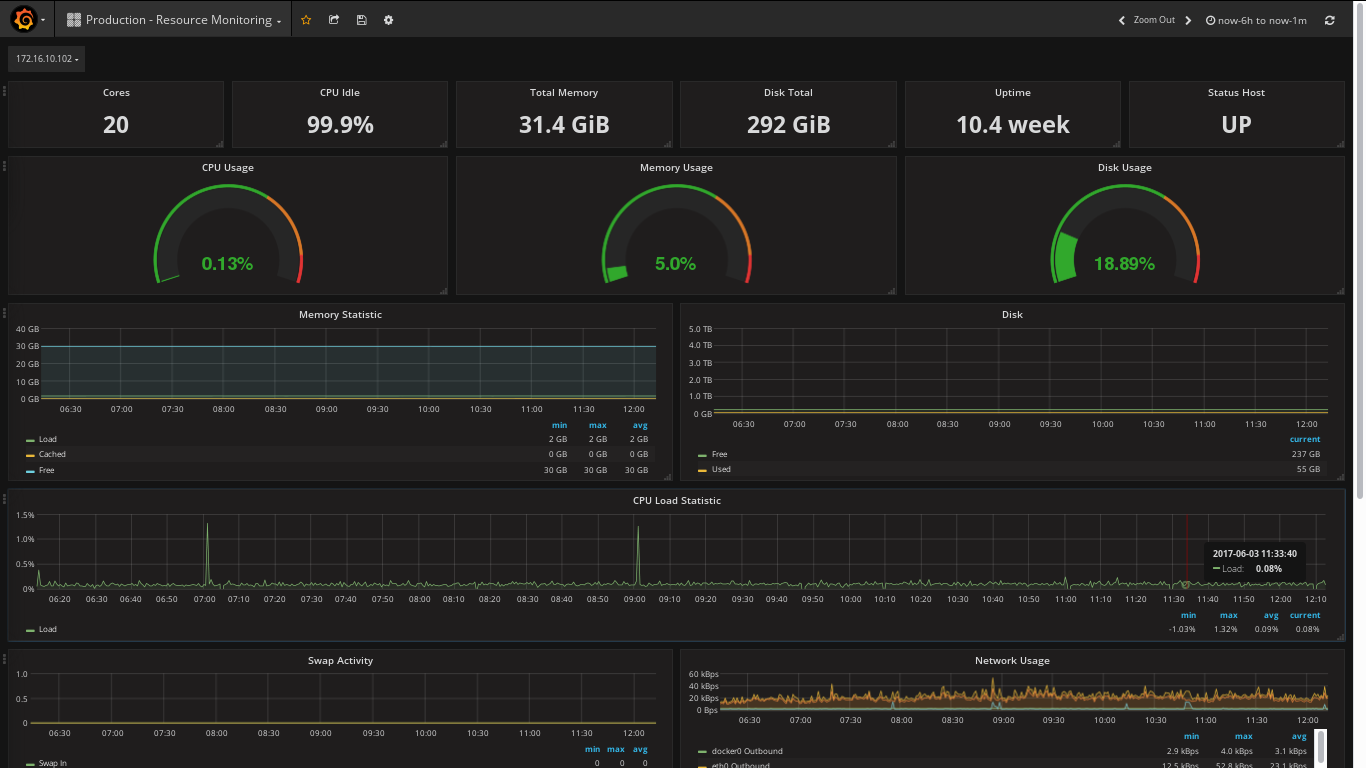
Ese fue el paso a paso para deployar nuestra app con una imagen de Docker y monitorearla a través de un cluster de Kubernetes con Prometheus para recolectar data y Grafana para visualizarla. Más tutoriales en https://grafana.com/grafana/dashboards.